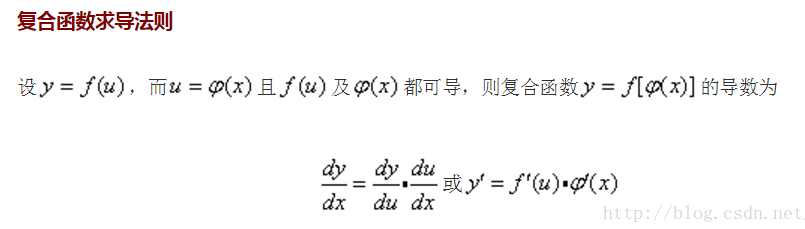Index
背景
在各种机器学习入门教程中,逻辑回归模型(Logistic/Logit Regression)经常被拿来作为入门的机器学习模型,各种面试中手推逻辑回归也变成了一个必考科目。看起来,逻辑回归模型好像很简单,甚至容易被认为是一个拍脑袋想出的naive的模型。在这里,想问问你,你真的了解逻辑回归么?(本篇博客的逻辑框架参考了夕小瑶的文章,她确实思路很赞)
常用的符号表示
| 符号 | 含义 |
|---|---|
| $p$ | 概率 |
| $h_\Theta(x)$ | 逻辑回归中判别函数 |
| $h_w(x)$ | 逻辑回归中判别函数(和上式相同,$w$和$\Theta$都表示参数) |
| $J(w)$ | 逻辑回归目标函数 |
浅入·逻辑回归
逻辑回归模型是用于二类分类的机器学习模型,有以下几个点千万注意:
- 不要说逻辑回归是一个回归模型啊!(虽然里面有线性回归的内容在,但它是做分类的)
- 不要说逻辑回归可以做多类分类啊!(那是二类分类器的组合策略问题,而与逻辑回归分类器本身的构造没有半毛钱关系)
我们用几个常见考题来浅入逻辑回归:
- 问题1,如何将一个$n$维向量$\vec{x}$映射为1个点$y$?
很容易想,将向量$\vec{x}$与另一个向量做内积,这个向量我们称为参数$\vec{\theta}$,即$\vec{\theta} = [\theta_1, \theta_2, \cdots, \theta_n]$,所以做内积就是$\vec{x}*\vec{\theta}^\mathrm{T}$(即行向量$\vec{x}$ 乘以 行向量$\vec{\theta}$的转置),最终会得到一个数。
- 问题2,如果$\vec{x} = [0, 0, \cdots, 0]$时,输出$y$永远等于1,那怎么办呢?
这时$\vec{x} * \vec{\theta}^\mathrm{T}$肯定也是$0$啊!所以为了解决这个问题,要再加个常数$b$,所以现在是$\vec{x} * \vec{\theta}\mathrm{T} + b$。为了看起来好看简洁,在$\vec{x}$的最开头加个$1$,把$b$扔到$\theta$的最开头,所以就成了新版的$\vec{x} * \vec{\theta}^\mathrm{T}$,当然此时有:
- 问题3,上述函数值域是$(-\infty,\ +\infty)$,但我们要得到的$0$或$1$,上述模型输出100000可咋办?
直观上,我们需要要把值域限制一下,将值域正负无穷改为$(0, 1)$。那咋改呢?自然想到了下面这个sigmoid函数:
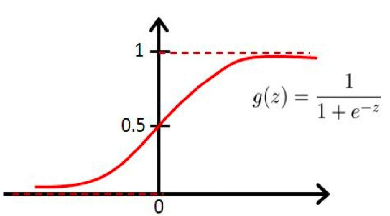
在这个函数的限制下,哪怕输入为正无穷,输出也不会大于1,同理,输入为负无穷,输出也不会为小于-1。这时,我们只需要认为当模型输出值大于0.5时,就认为是逻辑1;当输出值小于0.5时,就认为是逻辑0。预测函数(假设函数)完成,可以给样本贴上类别标签了!
- 问题4,训练模型用的 损失函数/代价函数/目标函数 是什么呢?
大概率,你会毫不犹豫的说出交叉熵这三个字,至于为什么会利用到交叉熵,而不用最小二乘的loss呢?(因为用了sigmoid的非线性+最小二乘导致非凸哈,感兴趣自己画一下)另外,与其相关的自信息、熵、KL散度、二项分布的交叉熵、最大似然等概念,你是否知道呢?(这里先不扯了,最大似然取对数也可以推出交叉熵这个loss)。它的一般形式如下:
其中,$p$代表真实分布,可以理解为真实概率,在二分类(二项分布)中,可以认为是label(因为只有0和1,它能当成概率);$q$代表非真实分布,可以理解为我们的预测概率。所以上述交叉熵的一般形式推广到逻辑回归(二分类、二项分布)中作为损失函数的形式如下:
这公式看起来很不错呀,仔细一看也看明白,反正当类别预测值与实际类别完全对起来的时候,$J(\Theta$确实等于0的。
- 问题5,如何优化上述目标函数呢?
答案很清晰了,梯度下降应该已经被说烂了吧。除了这个,那你知道为啥不用解析解、怎么应用牛顿法么?(解析解问题参见reference,它的推导有些小问题,但大致思路是对的,以两个特征为例,因为交叉熵loss和非线性函数,导致求解析解的方程中出现$w1*w2$,而不单纯是$w1,w2$的方程,无法求解)。最后,我们给出梯度下降所需的最终求导公式(过程参见手推图片,我太懒了,不想latex公式了)。

最后,等到$J(\Theta)$收敛到最优值,就得到了最优模型参数$\Theta$
- 问题6,上面几个问题看起来没毛病哈,难道每一步真的都是这么恰好的信手拈来的吗?
Too young too simle, naive !!!
深出·逻辑回归
逻辑 · 回归
回归是一个基础概念,一个抽象而准确的描述是“回归即为两个或多个随机变量之间的相关关系建立数学模型”,设想一下,如果我们仅考虑两个随机变量,并且将其中一个随机变量看作机器学习的输入,也就是特征向量X,将另一个随机变量看作机器学习的输出,也就是类别预测y。那么回归就是用一个数学模型直接描绘出X到y的映射关系
想一想我们之前的朴素贝叶斯模型是怎么用X训练模型求y的?是不是用贝叶斯定理呀~也就是下面这样:
等式左边就是随机变量y,而等式右边并不是直接用X表示的,而是用其他东西间接描述y。所以!回归就是要直接用X描绘出y!是直接!
- 当随机变量X与随机变量y呈线性关系时,如果我们要用回归模型来描述这两个随机变量的关系,那么这里的回归模型是什么样子的呢?相信机智的你肯定想到啦,这里就是高中就学过的线性回归模型:y=ax+b
- 当随机变量X与随机变量y呈逻辑关系时呢?(逻辑不就是0/1嘛),也就是说当随机变量X取某值时,随机变量Y为某一个逻辑值(0或1),那么这里的回归模型是什么样子的呢?相信机智的你肯定想到啦,这里就是大学都没学过的逻辑回归模型(你是不是知道了为啥叫做逻辑回归)
其实我们仔细想一下,逻辑回归模型是难以像线性回归一样直接写出类似于$y=ax+b$这么简洁的形式的,因为y的取值为离散的,只有0和1,所以要怎么表示呢?当然是用模型分别表示y取0的概率和y取1的概率了。也就是用模型表示出$p(y=1|X)$和$p(y=0|X)$
其实为某种形式的回归建立数学模型并不是一件容易的事情,经过先烈的曲折探索,得出了一个神奇的logit函数:
诶?看似简洁,然而有什么用呢?里面既没有x也没有y呀?
后验概率表示 in Logistic
先等等,还记得深度学习中经常加在神经网络的顶层来求后验概率的Softmax函数吗?对就是下面这个熟悉的函数:
对于我们的二分类问题来说,有$p(y=0|X)+p(y=1|X)=1$,如果我们令logit公式中的$q=p(y=1|x)$呢?然后$p(y=1|x)$用softmax函数表示呢?看看下面优美的推导:
这时候,$x^\mathrm{T} \Delta w$的值不就是反映感知机模型的输出嘛!(即$x^\mathrm{T} \Delta w > 0$则预测类别为正,$x^\mathrm{T} \Delta w < 0$则预测类别为负),所以logit函数我们再把$x^\mathrm{T} \Delta w$整理的好看一点,变成更正常的形式:$wx+b$,然后就可以得到下面的结论:
看,这就是我们前面苦苦寻找的逻辑回归模型!随机变量X与随机变量Y的关系竟然直接纳入了一个模型下面!也就是说后验概率直接用随机变量X表示了出来!而不是像贝叶斯定理一样间接表示后验概率。(这里其实就是判别模型和生成模型的区别啦,涉及一些概念,比如先验概率、后验概率、似然概率等,以后有机会再扯把!)
极大似然估计 in Logistic
有了上面直接表示的后验概率,于是建立似然函数,通过极大似然估计来确定模型的参数。因此设:
似然函数就表示为:
对数似然函数即:
也就是本文的“浅入”环节的损失函数啦,原来是正儿八经的一步步推出来的!剩下的就交给梯度下降法优化出模型参数吧!
Logit函数
Logit可以理解成Log-it,这里的it指的是Odds(“几率”,等于$p/1-p$)。一个Logit变换的过程如下图所示:

在统计学中,Logit函数也称为log-odds函数,它可以将概率值p(区间为$[0, 1]$)映射到$(-\infty, +\infty)$,图像如下:
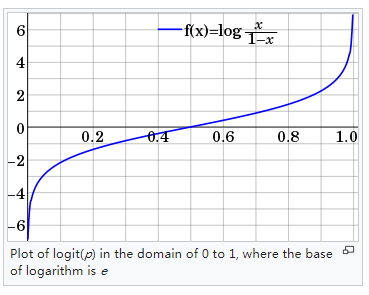
Logit函数的数学变换如下:
Logit与Logistic的恩怨情仇
当我们讨论Logit模型时候,指的是下面这种形式:
注意,等号右侧是自变量的线性组合(是不是快想到了线性回归?)。当我们只考虑一个自变量时:
两边同时做指数运算:
最后,整理一下,可以得到:
哎呦,你看上式不就是Logistic模型么。所以这两个模型对应的函数,其实是互逆的。小结一下:
- Logit模型的左侧是Odds的对数,而Logistic模型的左侧是概率
- Logit模型的右侧是一个线性结构,而Logistic模型的右侧是非线性的
- 二者可以互为逆函数
Softmax与Sigmoid的血缘关系
我们已经知道,在逻辑回归中,用于预测样本类别的假设函数为
大佬们先忽略偏置项参数和向量转置这种细节哈,我们说临界点确定的问题,我们将$h_w(x)>0.5$的样本预测为正类别(记为类别1),将$h_w(x)<0.5$的样本预测为负类别(记为类别0)。因此对于$sigmoid(z)$函数来说,$z=0$的点就是用来分类的临界点。所以在逻辑回归中,$wx=0$的点就是分类的临界点。
- 可是你有想过为什么吗?是的,这并不是拍脑袋决定的。换一种问法,你知道$wx$是代表什么意思吗?它难道仅仅代表了“特征向量与模型参数做内积”这么肤浅的含义吗?
首先,模型参数$w$是个向量,维数与样本的维数一致。这个所谓的模型参数$w$本质上是$w_{y=1} - w_{y=0}$,记为$\Delta w$。如何理解被拆出来的这两个$w_{y=1}, w_{y=0}$呢?
其实只要把这个$w_{y=1}$向量看作是对类别1的直接描述,将$w_{y=0}$向量看作是对类别0的直接描述,新世界的大门就打开了。在逻辑回归模型中,本质上用来预测类别的临界点就是$wx$,也就是$w_{y=1}x - w_{y=0}x$,这代表什么意思呢?
我们知道,对于向量a和向量b,假设它们的长度都为1,那么当向量a与向量b夹角最小时,它们的内积,也就是会最大。当然了,推广到更一般的说法,不限制a与b的长度,则当a与b夹角最小时,我们称a与b的余弦相似度最大
而两向量的夹角越小意味着什么呢?意味着这两个向量越相似呀,意味着越亲密呀。所以$w_{y=1}x - w_{y=0}x$就意味着类别1与特征向量$x$的亲密度减去类别0与$x$的亲密度,因此当逻辑回归的假设函数$h_w(x)>0.5$时,也就是$wx>0$时,就代表着特征向量$x$与类别1更亲密,因此类别预测为1。同样的道理,当x与类别0更亲密时,类别预测为0。
为了美观,我们直接用$w_1$代替$w_{y=1}$,用$w0$代替$w_{y=0}$:
如果我们令分子分母同除以$e^{- w_0 x}$得:
$w_1$与$x$的内积代表着$w_1$与$x$的亲密度,这个不就代表着“类别1与x的亲密度占$x$与所有类别亲密度之和的比例”吗,这不是只有两个类别时候的Softmax么?
既然是比例,那肯定是0到1之间的数呀~而这个比例又可以解读为什么呢?不就是类别1在$x$心中的分量吗?当类别1在$x$心中的分量超过类别0在$x$心中的分量时,我们的逻辑回归模型当然要把类别1嫁给$x$呀,也就是将类别1作为预测的类别!同时,这个分量越大,我们将类别1嫁给$x$后,会让$x$满意的概率就越大!所以这个比例又是类别1的后验概率$P(y=1|x)$呀!
看,一切都不是巧合吧。Sigmoid函数的意义,竟然如此深邃,其实它就是简化版的Softmax函数,这涉及到softmax其实有一个参数是冗余的,当面对sigmoid函数时候,二分类时只用一个参数$\Delta w$就能完整描述。
缘分,妙不可言,Softmax和Sigmoid就是这样!
相关引用
- Logit wikipedia
- 浅入深出被人看扁的逻辑回归
- 深入深出Sigmoid与Softmax的血缘关系
- Logit模型和Logistic模型有什么区别?
- Why is the error function minimized in logistic regression convex?
- 为什么LR的MLE无法求解析解?
Appendix
常见求导公式

常见求导法则

复合函数求导法则